How to remove duplicate data in SQL server.
For remove duplicate data in SQL Server, you can use various approaches. Below, I’ll outline a method using Common Table Expressions and the ROW_NUMBER() function, which is a commonly used and effective method to assign unique number to each row.
Identify Duplicates:
- Use the
ROW_NUMBER()function to assign a unique identifier to each row within a partition of duplicates.
Delete the Duplicates:
- Keep the first occurrence (based on some ordering, usually a primary key id column) and delete the rest.
Example:
Assume you have a table named test123 with columns id, FirstName, LastName, and Email, and Mobileno you want to remove duplicates based on Mobileno.
SQL Script
Here is a complete SQL script to achieve this:
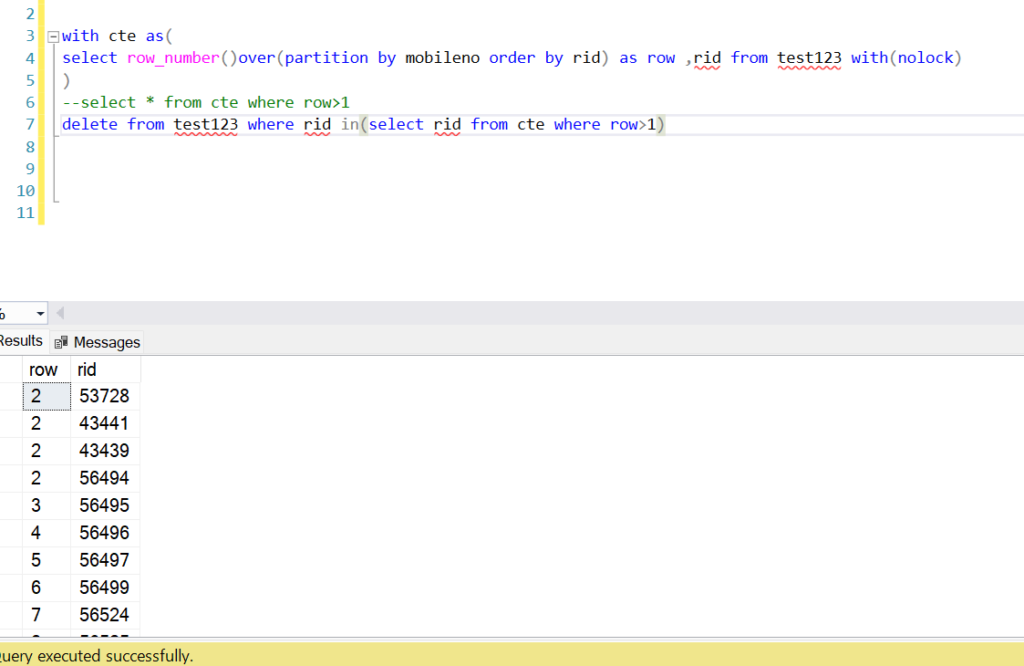
Explanation:
- Identify Duplicates with a CTE:
- The CTE uses
ROW_NUMBER()to assign a unique number to each row within partitions defined by Mobileno. - The
PARTITION BYclause groups rows that are considered duplicates. - The
ORDER BYclause ensures the row with the smallestidgetsRowNumber = 1.
- The CTE uses
- Delete the Duplicates:
- The
DELETEstatement removes rows whereRowNumberis greater than 1, effectively keeping only the first occurrence of each set of duplicates if want to take latest occurrence so we can use order by id desc.
Additional Considerations:
- Back Up Data: Before performing delete operations, always back up your data to prevent data loss.
- Take a complete backup of table by using below script to prevent data losses .
- select * into table_name from table
Following this method, you can efficiently remove duplicate rows from your SQL Server table while keeping your data consistent and clean.