SQL Server Identity Function Tutorial.
An identity column in SQL Server is a column that automatically generates a unique value for each row inserted into a table. This is typically used for primary key columns to ensure that each row can be uniquely identified. Here’s a detailed explanation of how identity columns work, how to create them, and some common use cases and functions associated with them.
Creating an Identity Column
When you create a table in SQL Server, you can define an identity column by specifying the IDENTITY property. The IDENTITY property takes two parameters:
- Seed: The initial value for the identity column.
- Increment: The value by which the identity column is incremented for each new row.
Syntax:
CREATE TABLE TableName ( ColumnName DataType IDENTITY(Seed, Increment),
-- Other columns );Example: Here i have created two table Employees1 and Employees2 by changing seed of identity column.
CREATE TABLE Employees1 (
EmployeeID INT IDENTITY(1,1) PRIMARY KEY,
FirstName NVARCHAR(50),
LastName NVARCHAR(50),
Email NVARCHAR(100)
)
CREATE TABLE Employees2 (
EmployeeID INT IDENTITY(100,1) PRIMARY KEY,
FirstName NVARCHAR(50),
LastName NVARCHAR(50),
Email NVARCHAR(100)
)
In this example:
EmployeeIDis the identity column.- The identity column starts at 1 (
Seed = 1) and at 100(Seed=100) and increments by 1 (Increment = 1) for each new row.
lets insert few rows in both table ( seed at 1,10) an identity column, you do not need to provide a value for the identity column. SQL Server automatically generates it.
INSERT INTO Employees1 (FirstName, LastName, Email)
VALUES ('Naren1', 'Dahiya1', 'nsdahiya8040@gmail.com'),
('Naren2', 'Dahiya2', 'nsdahiya8040@gmail.com'),
('Naren3', 'Dahiya3', 'nsdahiya8040@gmail.com'),
('Naren4', 'Dahiya4', 'nsdahiya8040@gmail.com'),
('Naren5', 'Dahiya5', 'nsdahiya8040@gmail.com');
INSERT INTO Employees2 (FirstName, LastName, Email)
VALUES ('Naren1', 'Dahiya1', 'nsdahiya8040@gmail.com'),
('Naren2', 'Dahiya2', 'nsdahiya8040@gmail.com'),
('Naren3', 'Dahiya3', 'nsdahiya8040@gmail.com'),
('Naren4', 'Dahiya4', 'nsdahiya8040@gmail.com'),
('Naren5', 'Dahiya5', 'nsdahiya8040@gmail.com');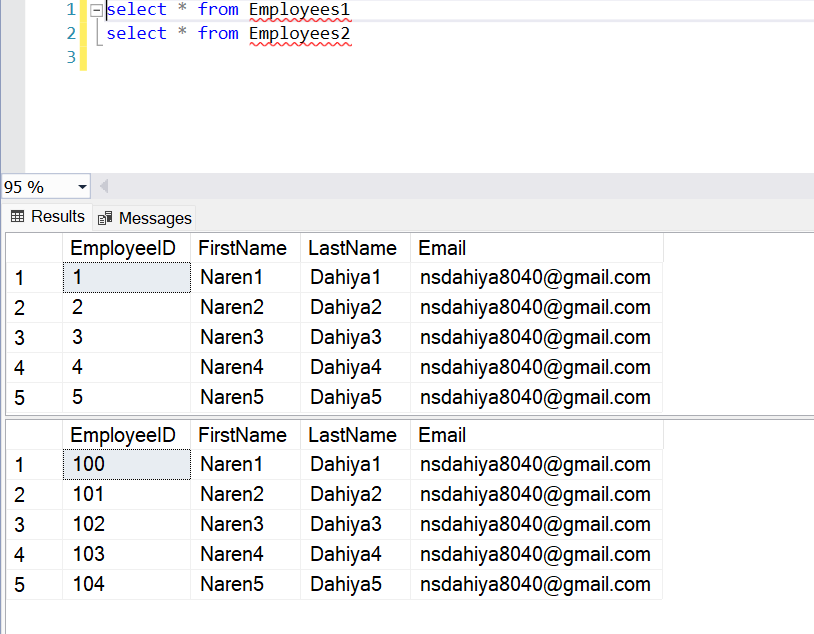
You can see the in both table employees1 and employees2 ,first employee gets an ID value 1 and 100 each new records ID value gets an increment of one.
We have some Important Identity function that works with identity column .let’s explore identity function with example:
- SQL @@IDENTITY Function
- SQL SCOPE_IDENTITY() Function
- SQL IDENT_CURRENT Function
- SQL IDENTITY Function
SQL @@IDENTITY Function:
Returns the last identity value generated for any table in the current session, but not necessarily in the current scope.
Syntax:
select @@identity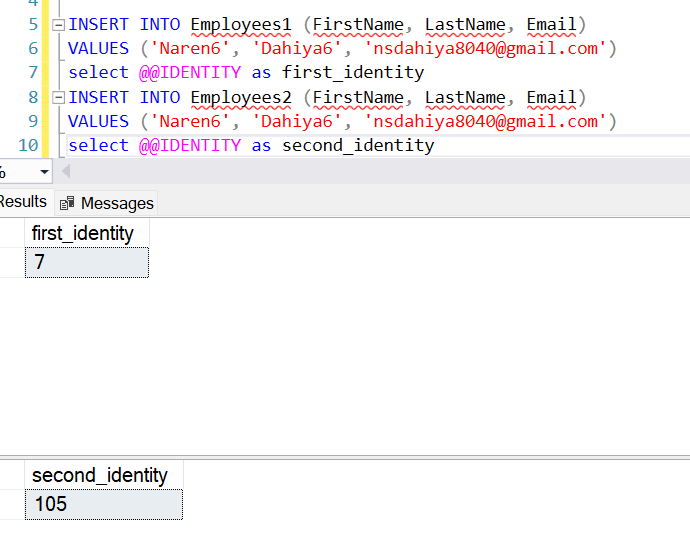
We use SQL @@identity function to return max identity value from table in current session .once row get inserted in a table @@identity function genrate a unique id for next row that is auto incremental.when we run other query @@identity function return NULL value .We can not use on remote server and linked server.
Explanation:
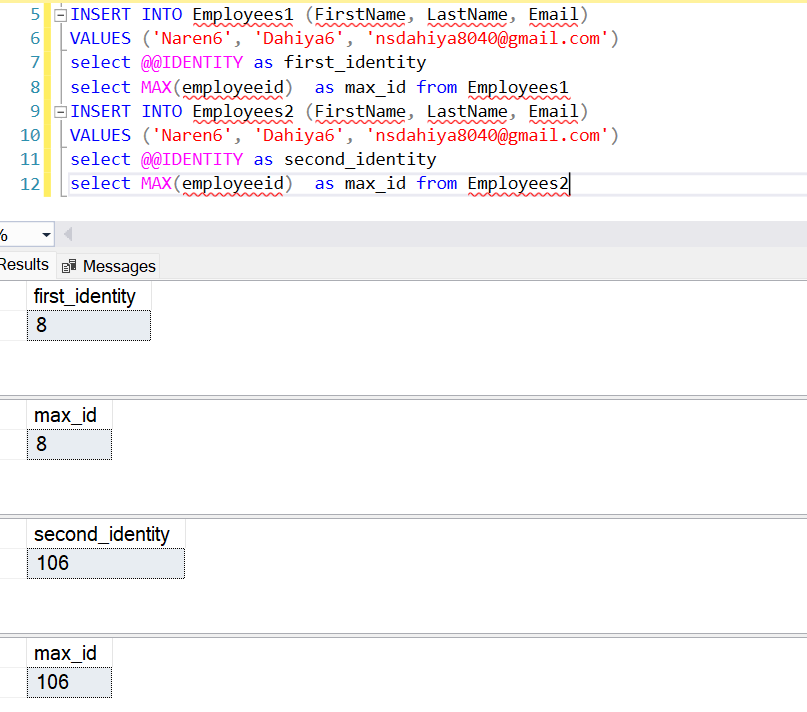
We have max identity is 8 and 106 in both table.once we inserted record in both table its incremented by 1 .we can check max identity value is 8 and 106.For verifying last inserted @@identity we can use select @@identity .
SQL IDENT_CURRENT(‘TableName’):
IDENT_CURRENT is a function in SQL Server that returns the last identity value generated for a specified table in any session and any scope. This function can be useful when you need to retrieve the most recent identity value for a table, regardless of which session or scope generated it.
Syntax:
IDENT_CURRENT('table_name')table_name: The name of the table for which you want to retrieve the last identity value.
IDENT_CURRENT is not limited by scope or session, meaning it retrieves the identity value generated by the last insert operation, regardless of where it occurred . A scope can be a module, trigger, function or a stored procedure.Let’s again insert rows in both Empoyees1 and Employee2 table and check max identity .
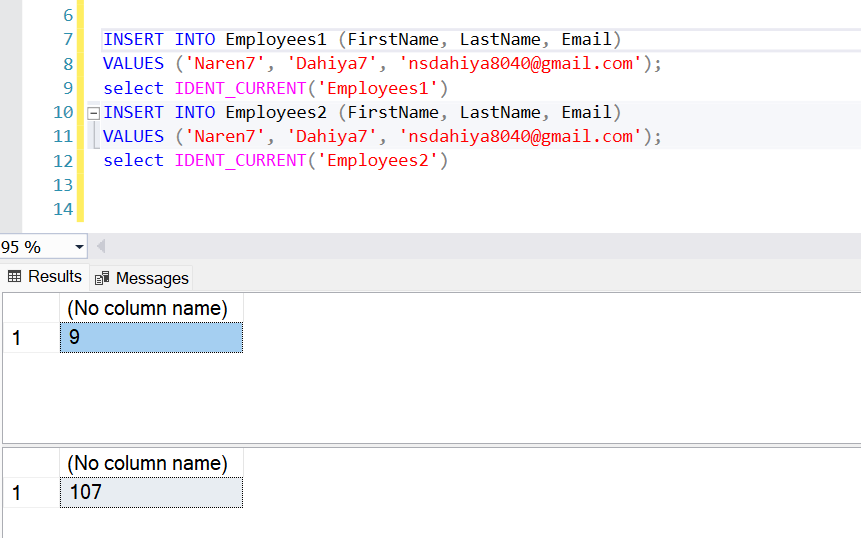
It does’nt metter where we running IDENT_CURRENT in current session or other session it always return max identity value from table if we run it before insertion it will return null value.
SQL SCOPE_IDENTITY() function:
The SCOPE_IDENTITY() function in SQL Server is used to retrieve the last identity value inserted into an identity column in the same scope and session. It is particularly useful when you need to obtain the identity value generated by an INSERT statement in the current session and scope, ensuring that it was generated within the same batch, stored procedure, or trigger.
Syntax:
select SCOPE_IDENTITY()In the following example, we see that both the @@IDENTITY and SCOPE_IDENTITY() return the same value in the current session and similar scope.
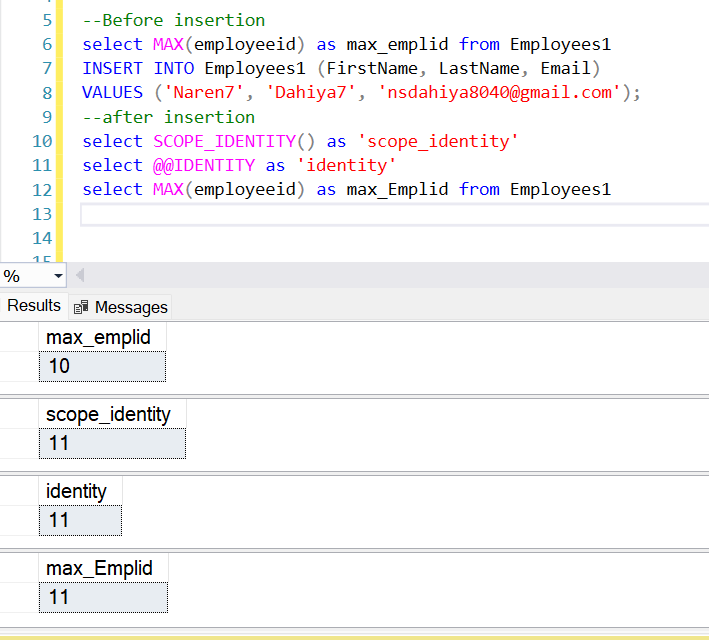
Let’s understand the difference between SCOPE_IDENTITY() and @@IDENTITY in other way get to know well about same scope and current session.
we can see that both the @@IDENTITY and SCOPE_IDENTITY() return the same value in the current session and similar scope.
Let’s consider we have two tables Employees1 and Employees2 table. We can create an dynamic insert query and one similer insertion query as we have done earlier. Once we insert any row on Employees1 and Employees2 by using dynamic query .
In the current session, we inserted data into the Employees1 table. It generates an identity in this table. The identity seed value is 1 for the Employees1 table and insert value in the Employees2 table. The identity seed value is 100 .
- We get the output 110 for the SELECT @@IDENTITY function
- SCOPE_IDENTITY function returns identity value under the current scope only. It gives output 14 for this function
--Before insertion
select MAX(employeeid) as max_employee1 from Employees1
select MAX(employeeid) as max_employee2 from Employees2
INSERT INTO Employees1 (FirstName, LastName, Email)
VALUES ('Naren7', 'Dahiya7', 'nsdahiya8040@gmail.com');
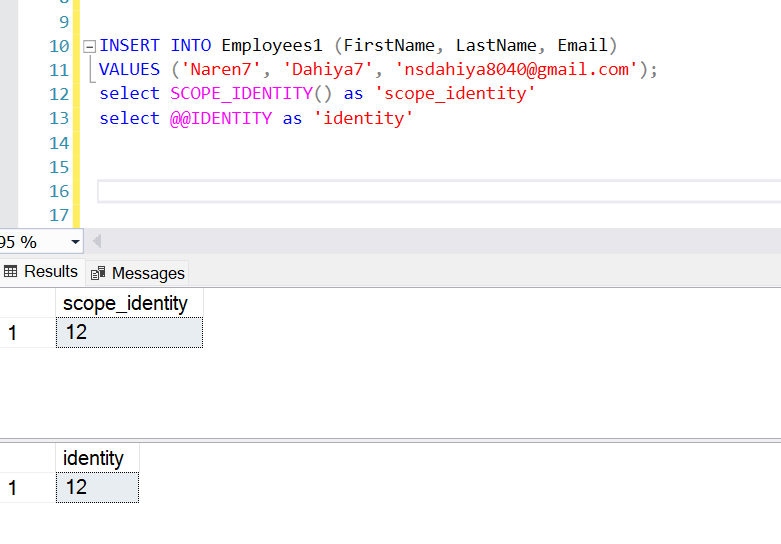
select SCOPE_IDENTITY() as 'scope_identity' --same session
select @@IDENTITY as 'identity' --same session
declare @query nvarchar(max)='INSERT INTO Employees2 (FirstName, LastName, Email)
VALUES (''Naren7'', ''Dahiya7'', ''nsdahiya8040@gmail.com'');'
exec (@query)
select SCOPE_IDENTITY() as 'scope_identity'--in current scope max inserted identity is 13
select @@IDENTITY as 'identity' --in current session max inserted identity is 109 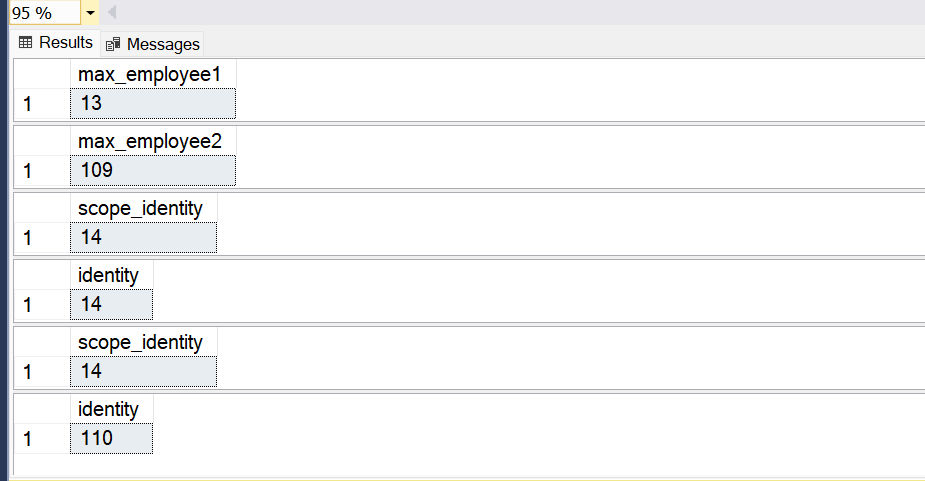
SQL IDENTITY Function:
In SQL Server, the IDENTITY property is not a function but a column property used to automatically generate unique values for new rows in a table. This property is typically used for creating primary key columns that auto-increment. Below is a detailed explanation of the IDENTITY property and how it can be used.
Syntax:
column_name data_type IDENTITY(seed, increment)column_name: The name of the column.data_type: The data type of the column, usuallyINTorBIGINT.seed: The initial value for the first row.increment: The value to be added to the seed for each subsequent row
Creating a Table with an IDENTITY Column
CREATE TABLE Employees ( ID INT IDENTITY(1,1) PRIMARY KEY, FirstName NVARCHAR(50), LastName NVARCHAR(50),emailid nvarchar(100),mobno nvarchar(15) );Inserting Data into a Table with an IDENTITY Column
When you insert data into a table with an identity column, you do not need to provide a value for the identity column. SQL Server will automatically generate it:
INSERT INTO Employees (FirstName, LastName, emailid,mobno) VALUES ('Naren', 'dahiya', 'xyz@gmail.com','857563647'), ('test', 'test', 'xyx@gmail.com','7645342');By understanding and using the IDENTITY property in SQL Server, you can efficiently manage auto-incrementing primary key columns and ensure unique identifiers for your table rows.
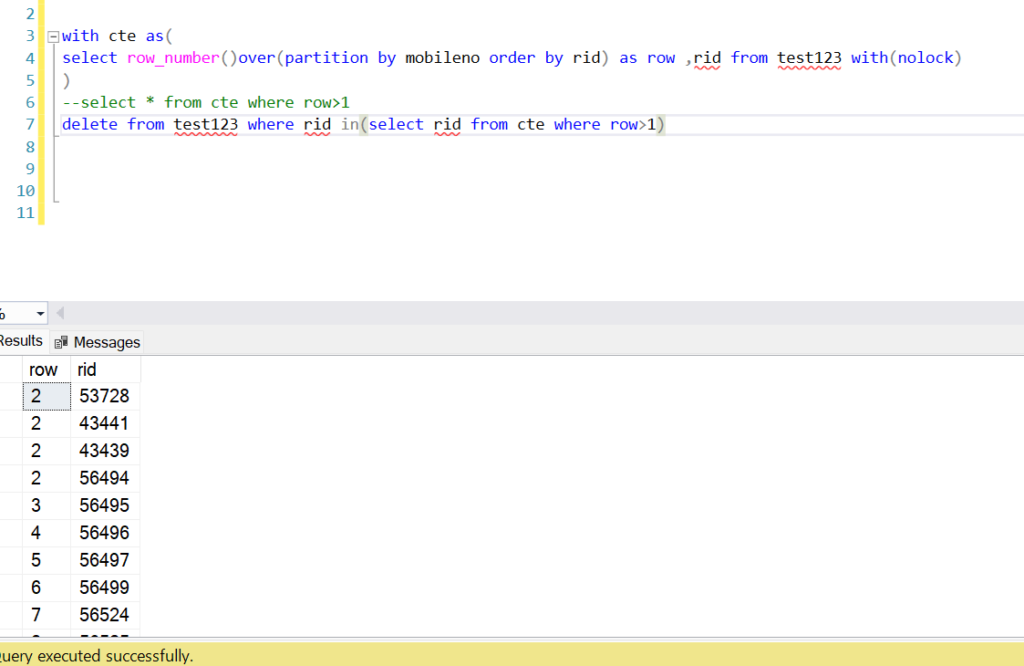
Resetting the identity column:
inserted row starts with a specified value. This can be particularly useful when you want to reset the identity column after deleting rows from a table or for testing purposes. Here’s how you can reset the identity column using the DBCC CHECKIDENT command.
Syntax:
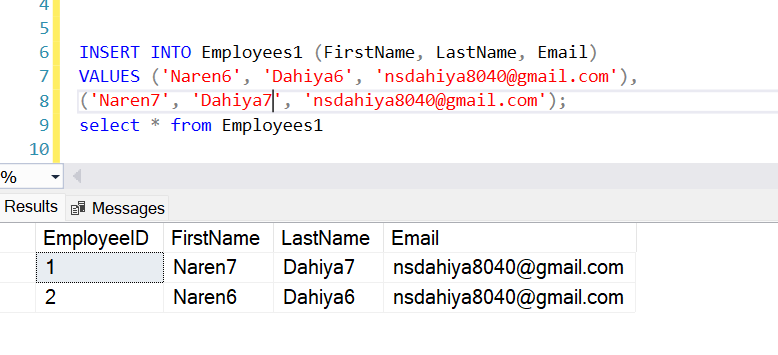
DBCC CHECKIDENT (table_name, RESEED, new_reseed_value);Let’s understand by example assume that we have Employee1 table with seed 1 meaning next row automatically increment by 1 ,let’s insert two row.
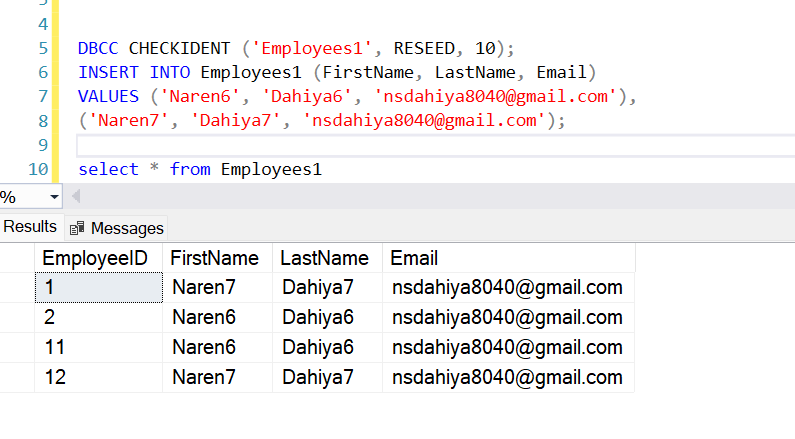
If you want to reset the identity column so that the next inserted row starts at a specific value, use DBCC CHECKIDENT. For example, to reset it to start at 10 .This means the next inserted row will have EmployeeID 11.
Reset to 0: If you want the next inserted row to start at 1, you can reset the identity to 0:
DBCC CHECKIDENT ('Employees', RESEED, 0);Reset After Deleting All Rows: If you delete all rows from a table and want to reset the identity column:
DELETE FROM Employees;
DBCC CHECKIDENT ('Employees', RESEED, 0);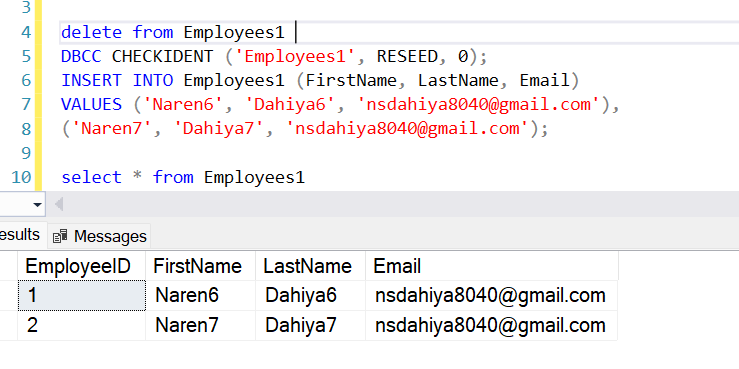
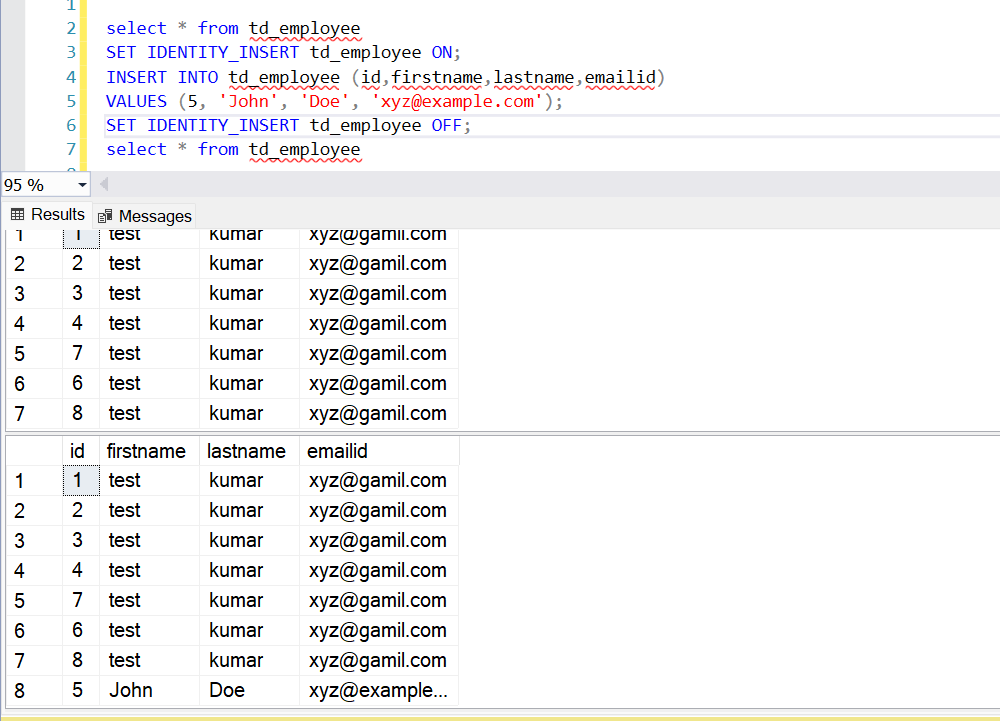
If we want to insert deleted identity then we can use identy_insert on and off property to insert missing identity make sure query dont take much time unless performance issue can occure on table.
Syntax:
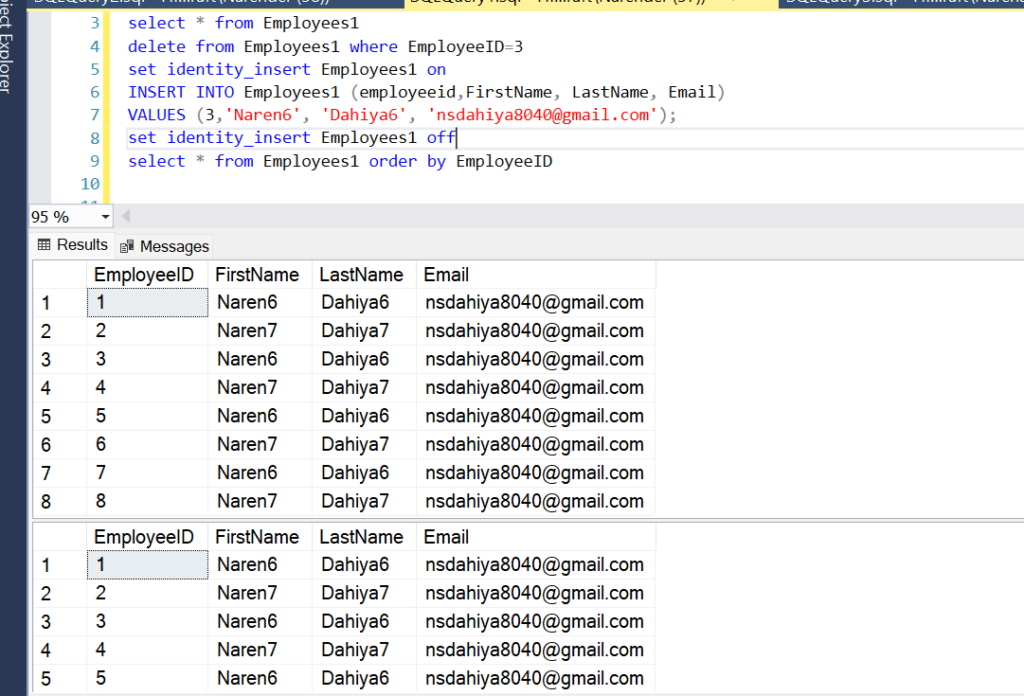
By understanding and using the IDENTITY property in SQL Server, you can efficiently manage auto-incrementing primary key columns and ensure unique identifiers for your table rows.